CPU 2.0时间来了?Flow PPU可使任何CPU性能素养100倍

6月13日讯息,近日芬兰知名的 VTT 技艺讨论中心旗下的一家科技初创公司Flow Computing告示一则爆炸性的声明称,其推出的并行处理单位 (PPU)不错“使任何 CPU 架构的性能提高 100 倍”!

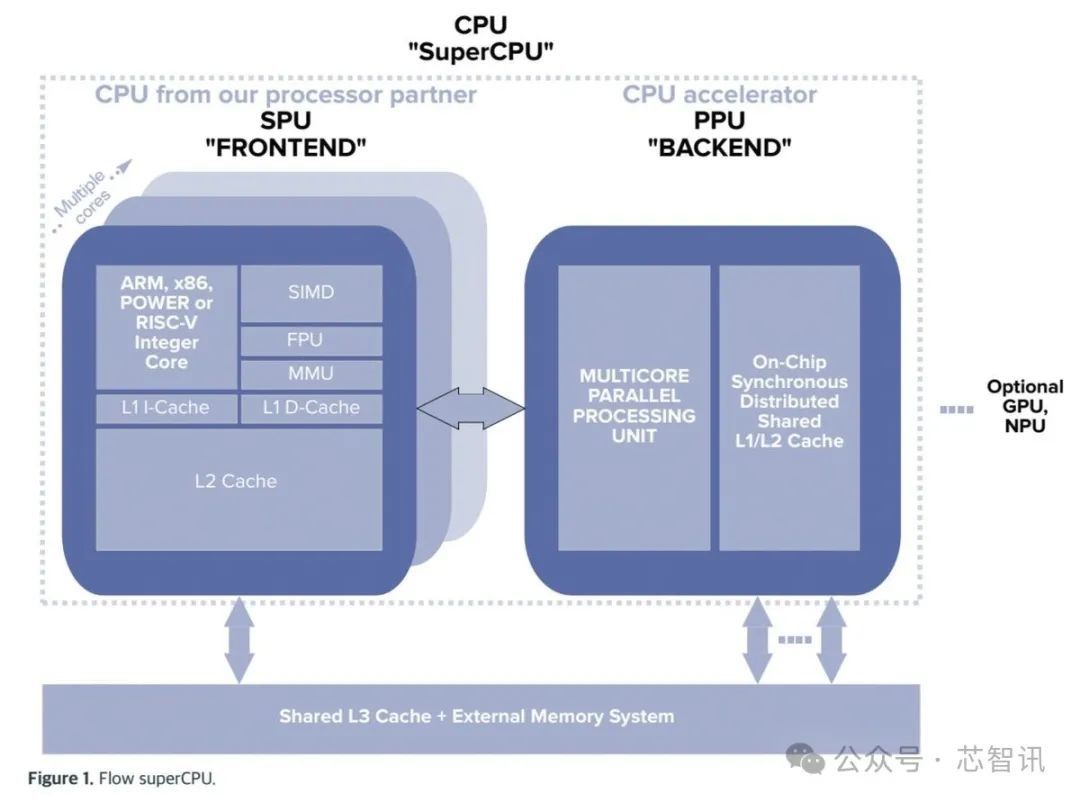
据先容,Flow的FPU大意集成到任何面前已有或行将推出的CPU联想架构、领导集或工艺几何结构中,可提供蜕变性的 100 倍加快,可立即用于基于冯·诺依曼的程序缱绻机联想,以竣事“CPU 2.0”级别的婉曲量。PPU还摈弃了在高性能应用程序中对 CPU 领导使用慷慨的 GPU 进行加快的需要。
Flow称,片上集成的 PPU 内核越多,得到的性能素养就越高。同期,SoC当中的其他缱绻单位也将受益于PPU的性能的素养,以及PPU对CPU性能的素养。
此外,通过Flow提供的编译器对 PPU 进行再行编译,PPU 与该 CPU 架构的每个现存软件应用程序可彻底向后兼容,不错大大加快统统现存软件和应用程序中的现存并行功能,而无需篡改任何软件。
从应用来看,Flow的打破性架构将可增强镶嵌式系统和数据中心的性能,适用于旯旮和云缱绻、AI 云、跨 5G/6G 的多媒体编解码器、自动驾驶汽车系统、军用级缱绻等用途。
当今,Flow 照旧在与来自宇宙各地的主要半导体供应商进行初步究诘,以寻求下一代 CPU 性能的“圣杯”。更多技艺细节将在 2024 年下半年公开分享。
Flow Computing逢迎首创东说念主兼首席本质官Timo Valtonen暗意:“在曩昔的几十年里,CPU性能惟一渐进式的改革,这导致了CPU内容上已成为缱绻中最薄弱的要津,因为它的限定架构并不睬念念。为了答允对更多缱绻性能的不休增长的需求,CPU性能的新时间已成为必要条目,这在很猛历程上是由东说念主工智能以及旯旮和云缱绻的需求股东的。Flow 筹谋通过其全新的并行性能单位 (PPU) 架构引颈 SuperCPU 蜕变,使任何 CPU 的性能素养 100 倍,不管架构若何,并具有彻底的向后软件兼容性。”
Butterfly Ventures的结伴东说念主兼逢迎首创东说念主Juho Risku也暗意:“由于CPU改革速率在曩昔十年中放缓,科技行业的每个行业王人继续受到影响。Flow 是这一趋势的第一个首要变革者,它提供了数倍的性能,而不是几个百分点。而且在咱们看来,Flow 将对缱绻阛阓的基线性能产生比量子缱绻等更无为的影响。尽管许多公司在东说念主工智能方面参预了无数资金,但通用缱绻将主导其本钱并扫尾其智商。Flow Computing正在通过使下一代SuperCPU松驰超过面前的行业迷惑者,如Apple M系列,Nvidia Grace,Google Axion和Microsoft Azure Cobalt 100来管制这个问题,“
据悉,Flow公司刚刚得到了 400 万欧元的种子轮融资。参与种子轮融资的实体包括Butterfly Ventures(领投)、FOV Ventures、Sarsia、Stephen Industries、Superhero Capital和芬兰商务促进局。
一、什么是并行处理单位?
据Flow公司官网先容,并行处理单位 (PPU) 是一个 IP 模块,不错与兼并芯片上的 CPU 风雅集成。它被联想为高度可竖立,以答允繁多用例的特定要求。
相沿的自界说选项包括:
PPU 中的内核数(4、16、64、256 等)
功能单位的数目和类型(如 ALU、PPU、MU、GU、NU)
片上存储器资源(缓存、缓冲区、暂存器)的大小
对领导集进行了修改,以补充 CPU 的领导集膨大
对 CPU 的修改很少,包括将 PPU 接口集成到领导聚会,并可更新 CPU 内核的数目,以愚弄新的性能水平。
Flow的参数化联想允许无为的定制,包括 PPU 内核的数目、功能单位的种类和数目以及片上存储器资源的大小。性能会跟着 PPU 内核数目的加多而加多。4 核的 PPU 十分适合智高腕表等袖珍确立,16 核 PPU 十分适合智高手机,而 64 核 PPU 可为 PC 提供出色的性能;256 核 PPU 最适合 AI、云和旯旮缱绻办事器等高需求环境,使它们大意松驰处理最坑诰的缱绻任务。
二、领有三大中枢上风
据先容,Flow的并行处理单位 (PPU)具有三大中枢上风:
1、Flow 创新的并行处理单位 (PPU) 将 CPU 性能素养 100 倍,草创了 SuperCPU 时间。
创新的并行处理单位 (PPU)专为彻底向后兼容而联想,可在再行编译后增强现存软件和应用程序。功能越并行,性能素养就越大。
同期,Flow的技艺还增强了通盘缱绻生态系统。比如,接济组件(矩阵单位、矢量单位、NPU 和 GPU)也可通过增强的 CPU 功能得到了增强的性能。这一切王人要归功于 PPU。
2、传统软件和应用程序速率提高 2 倍
Flow 的 PPU 不仅不错在不改变原始应用程序的情况下增强留传代码,而且在与再行编译的操作系统或编程系统库配对时也能提高性能。
因此,PPU不错匡助多样应用程序中大幅提高速率,荒谬是那些闪现并行性但受到传统基于线程的处理扫尾的应用程序。PPU 开释了这些应用的一说念后劲,而在以前的架构终无法竣事这么的性能显耀素养。
3、参数化联想
可竖立的参数化联想使PPU大意适合多种用途。一切王人不错定制,以答允多个用例的特定要求。PPU 内核数相沿4核、16核、64核、256核或更多功能单位(如 ALU、PPU、MU、GU 和 NU)的类型和数目。以致片上存储器资源(缓存、缓冲区和暂存器)的大小也不错把柄特定要求进行定制。性能的可膨大性与 PPU 内核的数目平直联系。
三、100倍的CPU性能素养是若何竣事的?
那么,Flow公司是若何通过其PPU来竣事关于CPU性能100倍素养的呢?据先容,Flow管制了 CPU 靠近的蔓延、同步和造谣级并行性方面的挑战,在这些技艺中的创新和谬误专利被实施到 PPU 中,它们将共同股东CPU竣事 100 倍的性能素养。
1、蔓延遮拦
面前冯·诺依曼架构的多核 CPU靠近内存访谒蔓延问题,尤其是分享访谒,对多核 CPU 来说是一个广泛的挑战。时常的内存存取会放慢本质速率,中枢间通讯采聚会导致额外的蔓延。传统的缓归档次结构会导致一致性和可伸缩性问题。
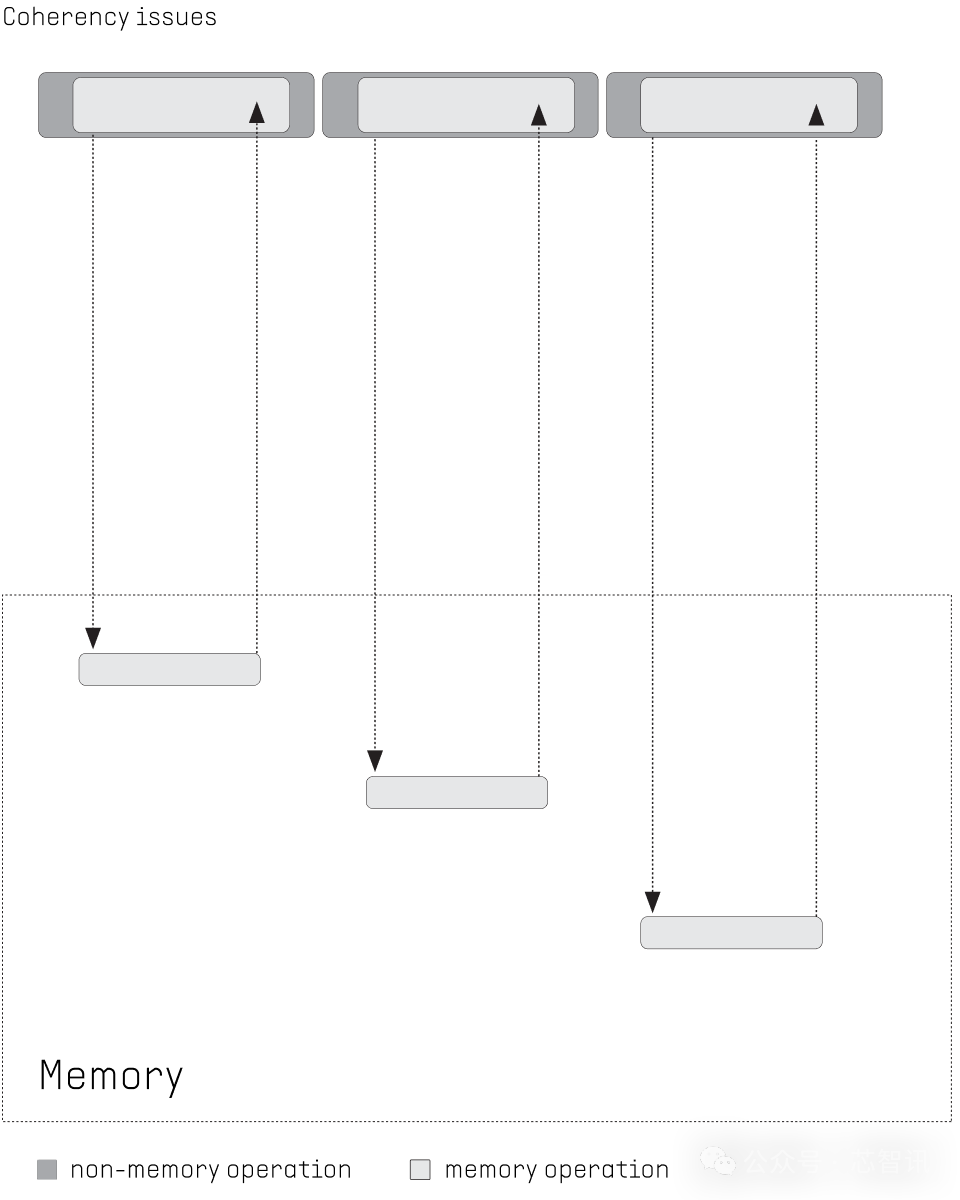
Flow公司的PPU则是将内存援用的蔓延,通过在访谒内存时本质其他线程来进行遮拦。这莫得一致性问题,因为莫得缓存摒弃在集合的前边。可膨大性通过高带宽片上集合提供。
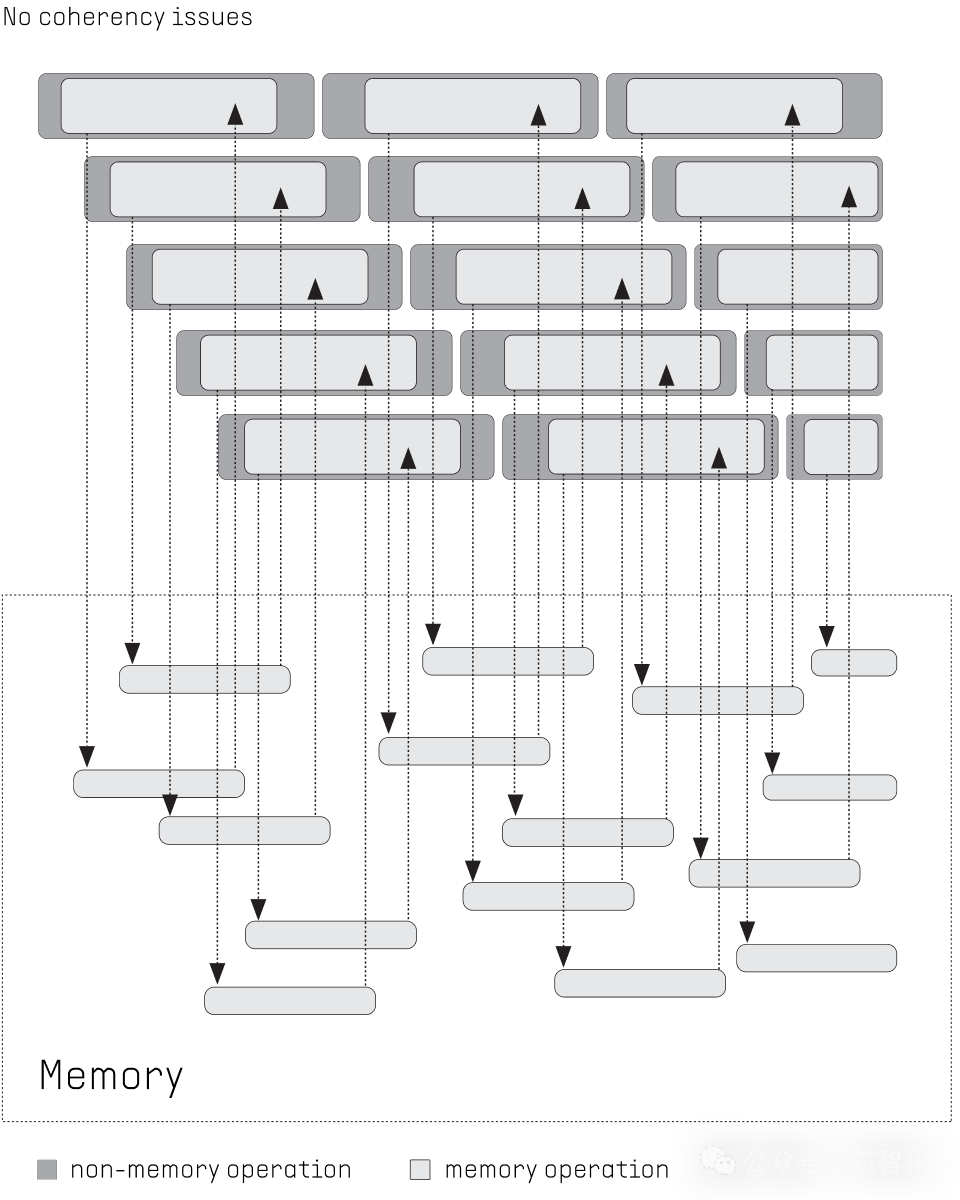
2、同步
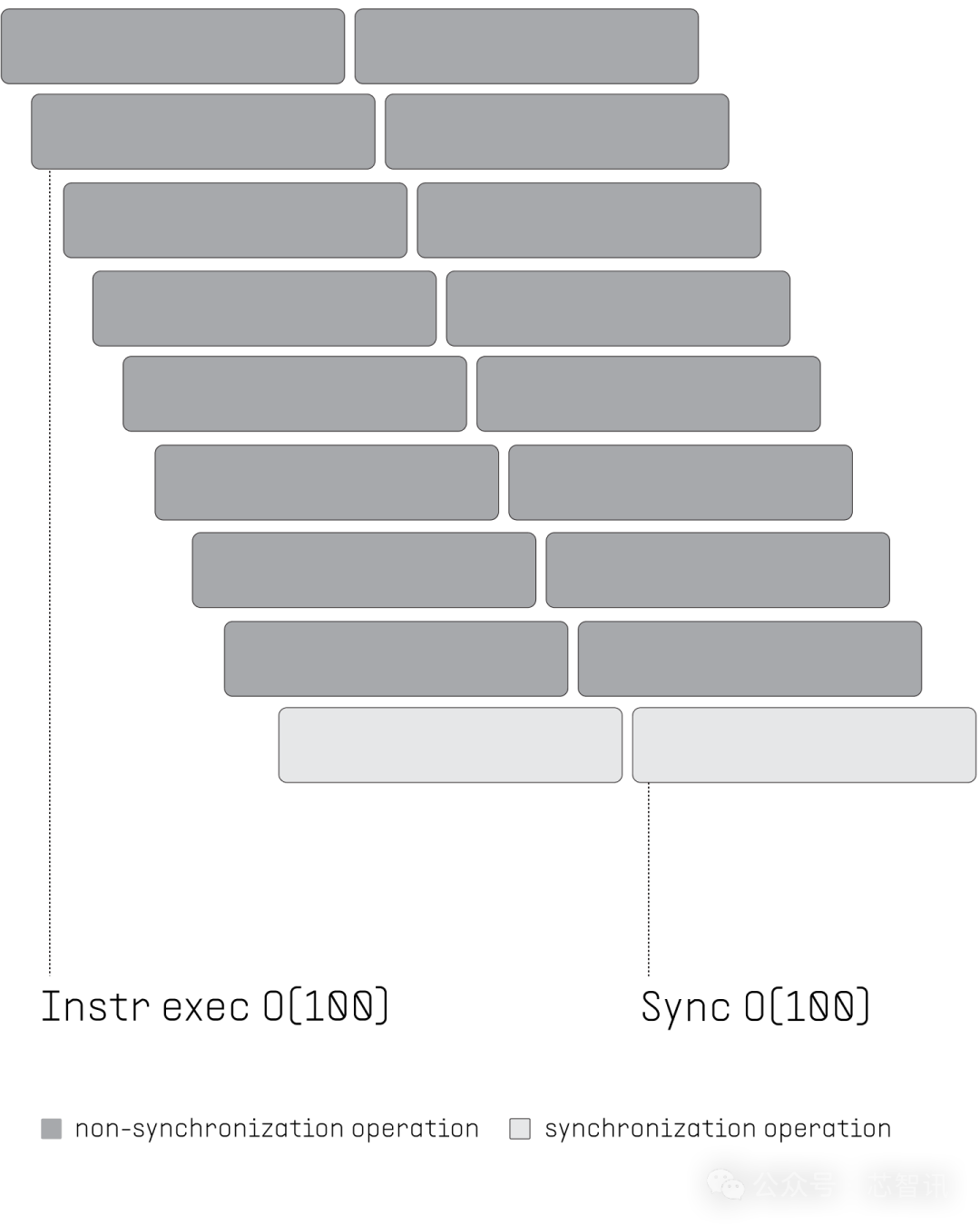
面前多核 CPU使用并行性会带来额外的挑战。由于 CPU 处理器内核固有的异步性,每当存在线程间依赖关系时,就需要同步线程。这些同步代价很大,平方需要 100 到 1000 个时钟周期。
比较之下, PPU每个设施只需要同步一次,因为线程在一个设施中互相孤苦,将支出本钱裁减到 1。同步与本质重迭,将支出本钱裁减到 1/100。
3、造谣ILP/LLP
面前多核 CPU对初级并行性的次优处理。惟一当领导是孤苦的时,才气在多个功能单位中本质多个领导。管说念危契机放慢领导本质速率。
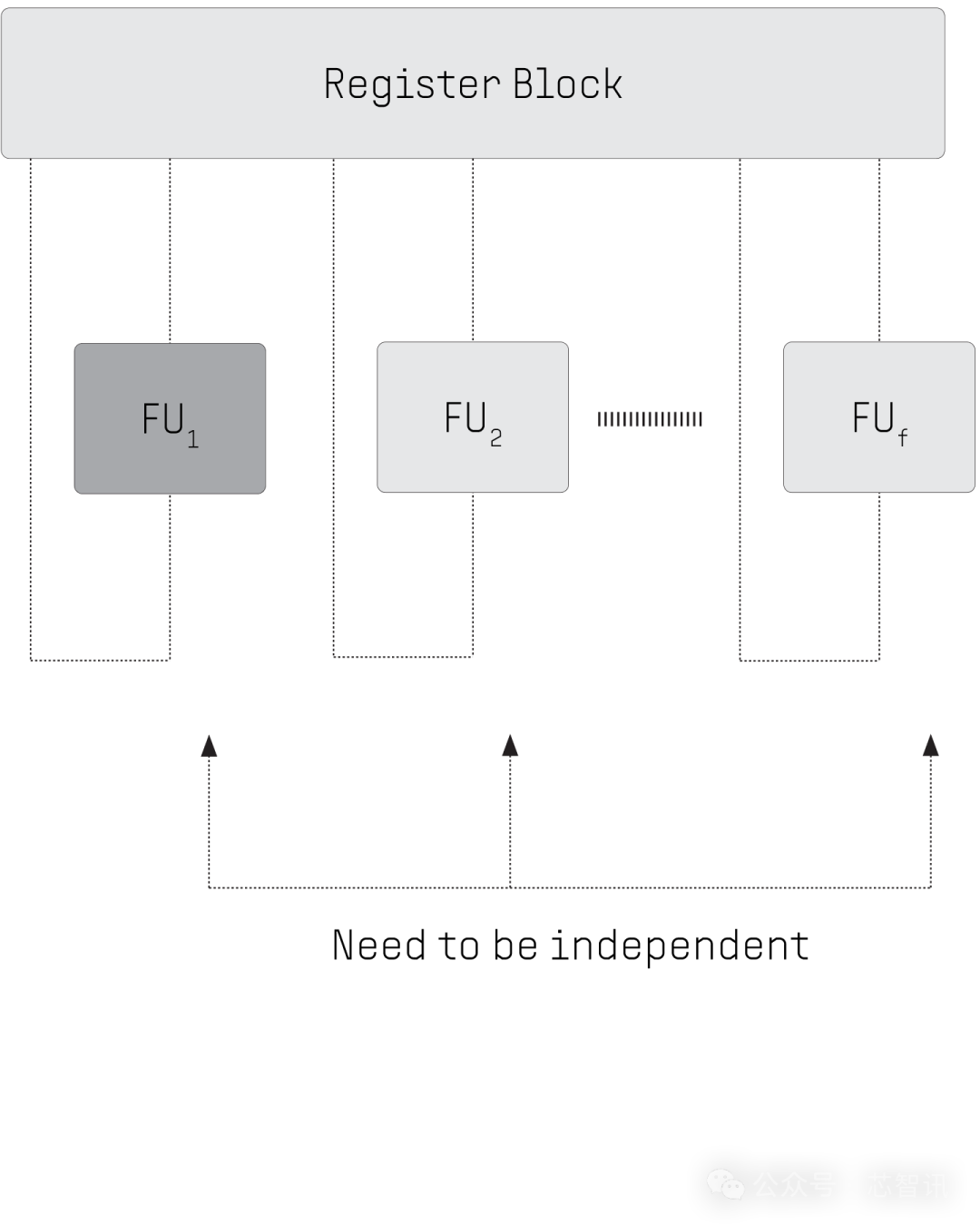
比较之下,PPU功能单位被组织为一个链,其中单位不错使用其前身的成果当作操作数。不错在本质的一个设施内本质依赖代码,摈弃管说念危机。
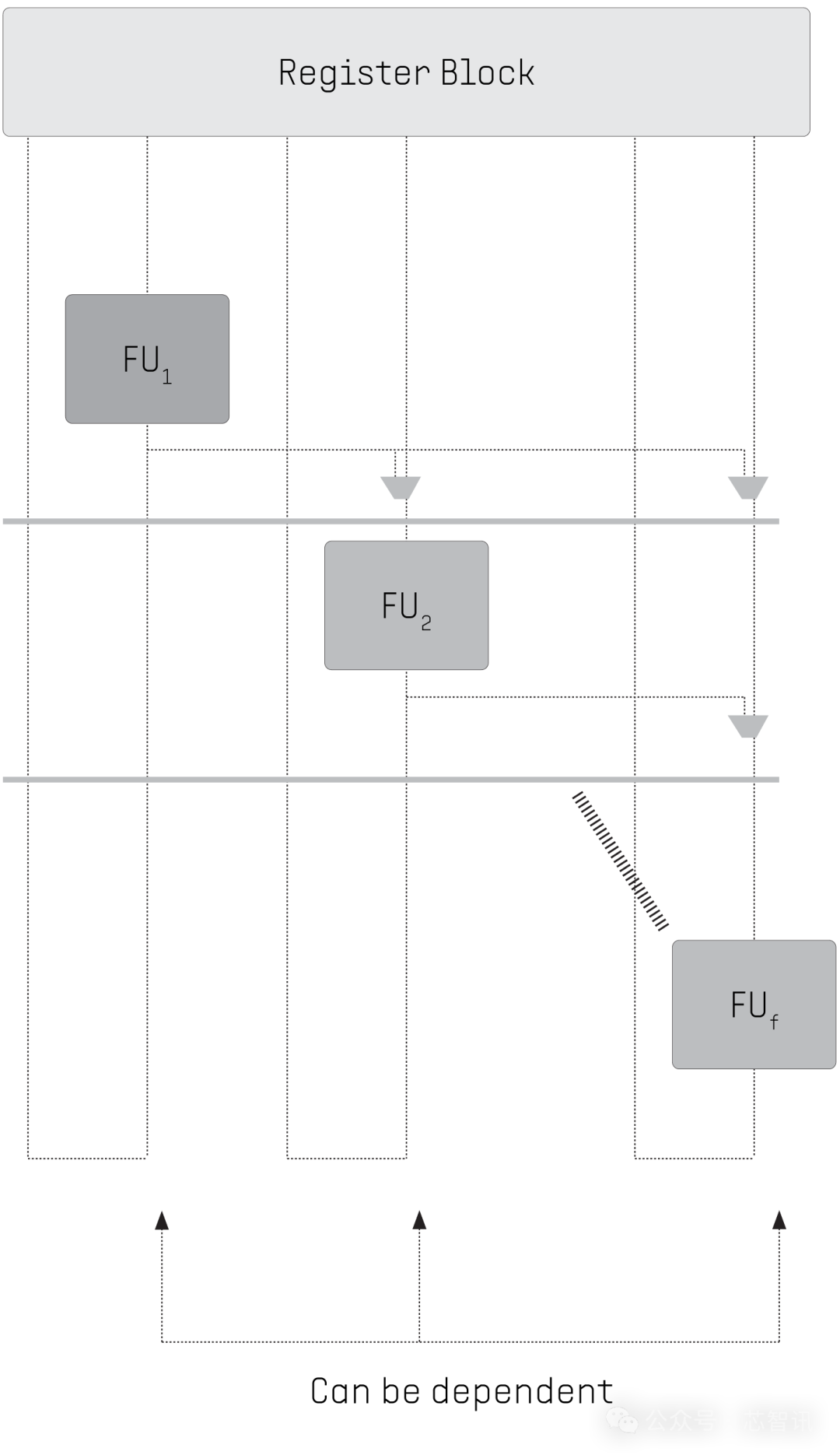
四、素养现存软件和应用程序的性能
Flow技艺彻底向后兼容统统现存的传统软件和应用程序。PPU 的编译器会自动识别代码的并行部分,并在 PPU 内核中本质这些部分。
此外,Flow 正在迷惑一种 AI 器用,以匡助应用程序和软件迷惑东说念主员识别代码的并行部分,并冷酷简化这些部分以竣事最大性能的措施。
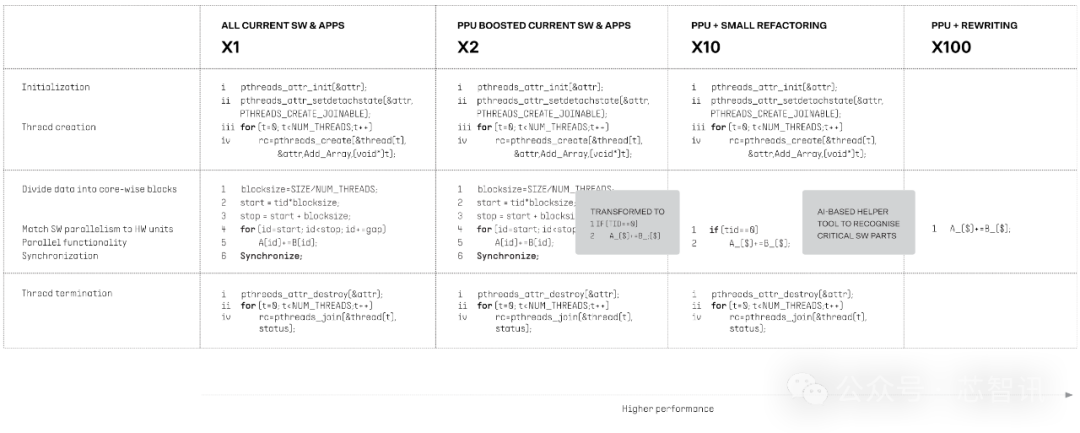
小结:
固然Flow暗意其PPU大意为任何面前的冯·诺依曼架构的CPU带来最高100倍的性能素养,然而并未给出明确的方向数据来进行解说,仅仅诠释了会从蔓延、同步和造谣ILP/LLP等方面进行为手来进行改革。况且正如其官网所先容的,PPU还领有4到256核的竖立,需要配备几许核PPU才气带来100倍性能素养,Flow并未解说。另外,软件的再行编译亦然竣事 100 倍性能改革的必要条目。该公司暗意,软件的再行编译不错使得现存代码的启动速率将提高 2 倍。
另外,PPU是并行处理单位,而GPU的上风亦然在于并行缱绻。Flow以致还暗意,PPU摈弃了在高性能应用程序中对 CPU 领导使用慷慨的 GPU 进行加快的需要。那么是否意味着,CPU+PPU的组合在某种历程上不错竣事超过GPU的AI加快智商?
Flow还在一份常见问题解答文档中解说了其 PPU 与当代 GPU 之间的主要分手。“PPU 针对并行处理进行了优化,而 GPU 针对图形处理进行了优化。”这家初创公司对比称:“PPU 与 CPU 的集成度更高,你不错将其视为一种协处理器,而 GPU 是一个孤苦缱绻单位,与 CPU 的流畅更为松散。”它还强调了 PPU 不需要单独内核偏合手可变并行宽度的迫切性。
Flow暗意,它将在本年下半年提供联系PPU的更多技艺细节。至于Flow PPU的生意化发达,它提到了与 AMD、Apple、Arm、Intel、Nvidia、Qualcomm 和 Tenstorrent 等公司协作的可能性。Flow 的 PR 强调了其对 IP 许可阵势的偏好,相通于Arm的授权阵势,客户需要付费获取其PPU IP,以便镶嵌到其CPU联想当中。
剪辑:芯智讯-浪客剑